Workload Prioritization
Overview
When dealing with services in resource-limited scenarios, it becomes paramount to prioritize key user experiences and business-critical features over less crucial tasks or background workloads. For instance, in an e-commerce platform, the checkout process must take precedence over functionalities like personalized recommendations, especially during resource shortage or high traffic. Aperture's Weighted Fair Queuing Scheduler (WFQ) enables such prioritization of flows over others based on their labels, ensuring user experience or revenue is maximized during overloads or other failure scenarios.
Configuration
This policy is based on the
Load Scheduling with Average Latency Feedback
blueprint. It defines service protection on
cart-service.prod.svc.cluster.local using a load scheduler and overload
detection is based on average latency similar to the
protection policy. In addition, workload
prioritization is specified in the load scheduler based on user types accessing
the service. User types are identified based on the value of a header label
http.request.header.user_type. Requests matching label value guest are
assigned a priority of 50, whereas those matching subscriber are given a
priority of 200.
The below values.yaml file can be generated by following the steps in the
Installation section.
- aperturectl values.yaml
# yaml-language-server: $schema=../../../../../../blueprints/load-scheduling/average-latency/gen/definitions.json
# Generated values file for load-scheduling/average-latency blueprint
# Documentation/Reference for objects and parameters can be found at:
# https://docs.fluxninja.com/reference/blueprints/load-scheduling/average-latency
policy:
# Name of the policy.
# Type: string
# Required: True
policy_name: workload-prioritization
# List of additional circuit components.
# Type: []aperture.spec.v1.Component
components: []
# The interval between successive evaluations of the Circuit.
# Type: string
evaluation_interval: "10s"
service_protection_core:
adaptive_load_scheduler:
load_scheduler:
# The selectors determine the flows that are protected by this policy.
# Type: []aperture.spec.v1.Selector
# Required: True
selectors:
- control_point: ingress
service: cart-service.prod.svc.cluster.local
# Scheduler parameters.
# Type: aperture.spec.v1.SchedulerParameters
scheduler:
workloads:
- label_matcher:
match_labels:
http.request.header.user_type: guest
parameters:
priority: "50"
- label_matcher:
match_labels:
http.request.header.user_type: subscriber
parameters:
priority: "200"
latency_baseliner:
# Tolerance factor beyond which the service is considered to be in overloaded state. E.g. if EMA of latency is 50ms and if Tolerance is 1.1, then service is considered to be in overloaded state if current latency is more than 55ms.
# Type: float64
latency_tolerance_multiplier: 1.1
# Flux Meter defines the scope of latency measurements.
# Type: aperture.spec.v1.FluxMeter
# Required: True
flux_meter:
selectors:
- service: cart-service.prod.svc.cluster.local
control_point: ingress
Generated Policy
apiVersion: fluxninja.com/v1alpha1
kind: Policy
metadata:
labels:
fluxninja.com/validate: "true"
name: workload-prioritization
spec:
circuit:
components:
- flow_control:
adaptive_load_scheduler:
dry_run: false
dry_run_config_key: dry_run
in_ports:
overload_confirmation:
constant_signal:
value: 1
setpoint:
signal_name: SETPOINT
signal:
signal_name: SIGNAL
out_ports:
desired_load_multiplier:
signal_name: DESIRED_LOAD_MULTIPLIER
observed_load_multiplier:
signal_name: OBSERVED_LOAD_MULTIPLIER
parameters:
alerter:
alert_name: Load Throttling Event
gradient:
max_gradient: 1
min_gradient: 0.1
slope: -1
load_multiplier_linear_increment: 0.025
load_scheduler:
scheduler:
workloads:
- label_matcher:
match_labels:
http.request.header.user_type: guest
parameters:
priority: "50"
- label_matcher:
match_labels:
http.request.header.user_type: subscriber
parameters:
priority: "200"
selectors:
- control_point: ingress
service: cart-service.prod.svc.cluster.local
max_load_multiplier: 2
- query:
promql:
evaluation_interval: 10s
out_ports:
output:
signal_name: SIGNAL
query_string: sum(increase(flux_meter_sum{flow_status="OK", flux_meter_name="workload-prioritization",
policy_name="workload-prioritization"}[30s]))/sum(increase(flux_meter_count{flow_status="OK",
flux_meter_name="workload-prioritization", policy_name="workload-prioritization"}[30s]))
- query:
promql:
evaluation_interval: 30s
out_ports:
output:
signal_name: SIGNAL_LONG_TERM
query_string: sum(increase(flux_meter_sum{flow_status="OK", flux_meter_name="workload-prioritization",
policy_name="workload-prioritization"}[1800s]))/sum(increase(flux_meter_count{flow_status="OK",
flux_meter_name="workload-prioritization", policy_name="workload-prioritization"}[1800s]))
- arithmetic_combinator:
in_ports:
lhs:
signal_name: SIGNAL_LONG_TERM
rhs:
constant_signal:
value: 1.1
operator: mul
out_ports:
output:
signal_name: SETPOINT
evaluation_interval: 10s
resources:
flow_control:
classifiers: []
flux_meters:
workload-prioritization:
selectors:
- control_point: ingress
service: cart-service.prod.svc.cluster.local
infra_meters: {}
Circuit Diagram for this policy.
Installation
Generate a values file specific to the policy. This can be achieved using the command provided below.
aperturectl blueprints values --name=load-scheduling/average-latency --version=v2.8.0 --output-file=values.yaml
Adjust the values to match the application requirements. Use the following command to generate the policy.
aperturectl blueprints generate --name=load-scheduling/average-latency --values-file=values.yaml --output-dir=policy-gen --version=v2.8.0
Apply the policy using the aperturectl CLI or kubectl.
- aperturectl
- kubectl
Pass the --kube flag with aperturectl to directly apply the generated policy
on a Kubernetes cluster in the namespace where the Aperture Controller is
installed.
aperturectl apply policy --file=policy-gen/policies/load-scheduling.yaml --kube
Apply the policy YAML generated (Kubernetes Custom Resource) using the above
example with kubectl.
kubectl apply -f policy-gen/configuration/load-scheduling-cr.yaml -n aperture-controller
Policy in Action
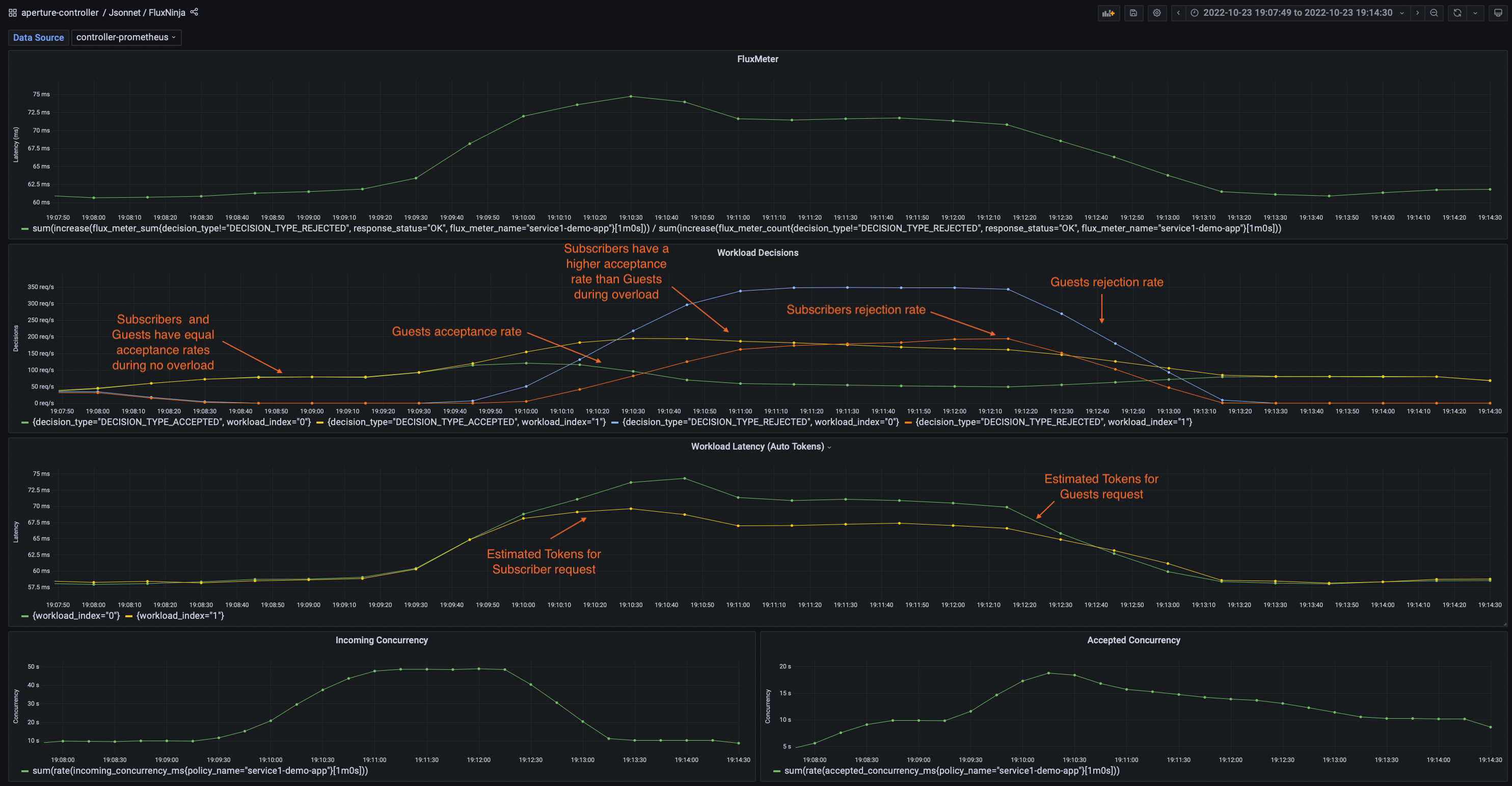
The traffic generator in this scenario is configured to generate similar traffic pattern (number of concurrent users) for 2 types of users - subscribers and guests.
The below dashboard shows that, during overload periods, requests from
subscriber users have a higher acceptance rate than those from guest users.
Demo Video
The below demo video shows the basic concurrency limiter and workload prioritization policy in action within Aperture Playground.