Load-based Auto Scaling
The following policy is based on the Service Protection with Average Latency Feedback blueprint.
Overview
Responding to fluctuating service demand is a common challenge for maintaining stable and responsive services. This policy introduces a mechanism to dynamically scale service resources based on observed load, optimizing resource allocation and ensuring that the service remains responsive even under high load.
This policy employs two key strategies: service protection and auto-scaling.
- Service Protection: Based on the trend of observed latency, the service gets protected from sudden traffic spikes using a Load Scheduler component. Load on the service is throttled when the observed latency exceeds the long-term trend by a certain percentage threshold. This ensures the service stays responsive even under high load.
- Auto-Scaling: The auto-scaling strategy is based on the throttling behavior of the service protection policy. An Auto Scaler component is used to dynamically adjust the number of service instances in response to changes in load. This load-based auto-scaling is enacted by a scale-out Controller that reads Load Scheduler signals. The service replicas are scaled out when the load is being throttled, effectively scaling resources to match the demand. During periods of low load, the policy attempts to scale in after periodic intervals to reduce excess replicas.
By combining service protection with auto-scaling, this policy ensures that the number of service replicas is adjusted to match persistent changes in demand, maintaining service stability and responsiveness.
Configuration
This policy, provides protection against overloads at the
search-service.prod.svc.cluster.local service. Auto-scaling is applied to
the Deployment search-service with a minimum of 1 and a maximum of 10
replicas.
To prevent frequent fluctuation in replicas, scale-in and scale-out cooldown
periods are set to 40 and 30 seconds, respectively. A periodic scale-in
interval of 60 seconds is also set to reduce excess replicas during periods of
low load.
- aperturectl values.yaml
# yaml-language-server: $schema=../../../../../../blueprints/policies/service-protection/average-latency/gen/definitions.json
# Generated values file for policies/service-protection/average-latency blueprint
# Documentation/Reference for objects and parameters can be found at:
# https://docs.fluxninja.com/reference/blueprints/policies/service-protection/average-latency
policy:
# Name of the policy.
# Type: string
# Required: True
policy_name: load-based-auto-scale
service_protection_core:
adaptive_load_scheduler:
load_scheduler:
# The selectors determine the flows that are protected by this policy.
# Type: []aperture.spec.v1.Selector
# Required: True
selectors:
- control_point: ingress
service: search-service.prod.svc.cluster.local
latency_baseliner:
# Tolerance factor beyond which the service is considered to be in overloaded state. E.g. if EMA of latency is 50ms and if Tolerance is 1.1, then service is considered to be in overloaded state if current latency is more than 55ms.
# Type: float64
latency_tolerance_multiplier: 1.1
# Flux Meter defines the scope of latency measurements.
# Type: aperture.spec.v1.FluxMeter
# Required: True
flux_meter:
selectors:
- control_point: ingress
service: search-service.prod.svc.cluster.local
components:
- auto_scale:
auto_scaler:
scaling_backend:
# Kubernetes replicas scaling backend.
# Type: aperture.spec.v1.AutoScalerScalingBackendKubernetesReplicas
# Required: True
kubernetes_replicas:
# Kubernetes object selector.
# Type: aperture.spec.v1.KubernetesObjectSelector
# Required: True
kubernetes_object_selector:
agent_group: default
api_version: apps/v1
kind: Deployment
name: search-service
namespace: prod
# Minimum number of replicas.
# Type: string
# Required: True
min_replicas: "1"
# Maximum number of replicas.
# Type: string
# Required: True
max_replicas: "10"
# Dry run mode ensures that no scaling is invoked by this auto scaler.
# Type: bool
dry_run: false
scale_in_controllers:
- alerter:
alert_name: Auto-scaler is scaling in
controller:
periodic:
period: "60s"
scale_in_percentage: 10
scale_out_controllers:
- alerter:
alert_name: Auto-scaler is scaling out
controller:
gradient:
in_ports:
setpoint:
constant_signal:
value: 1
signal:
signal_name: DESIRED_LOAD_MULTIPLIER
parameters:
slope: -1
# Parameters that define the scaling behavior.
# Type: aperture.spec.v1.AutoScalerScalingParameters
# Required: True
scaling_parameters:
scale_in_alerter:
alert_name: "Auto-scaler is scaling in"
scale_in_cooldown: "40s"
scale_out_alerter:
alert_name: "Auto-scaler is scaling out"
scale_out_cooldown: "30s"
Generated Policy
Circuit Diagram for this policy.
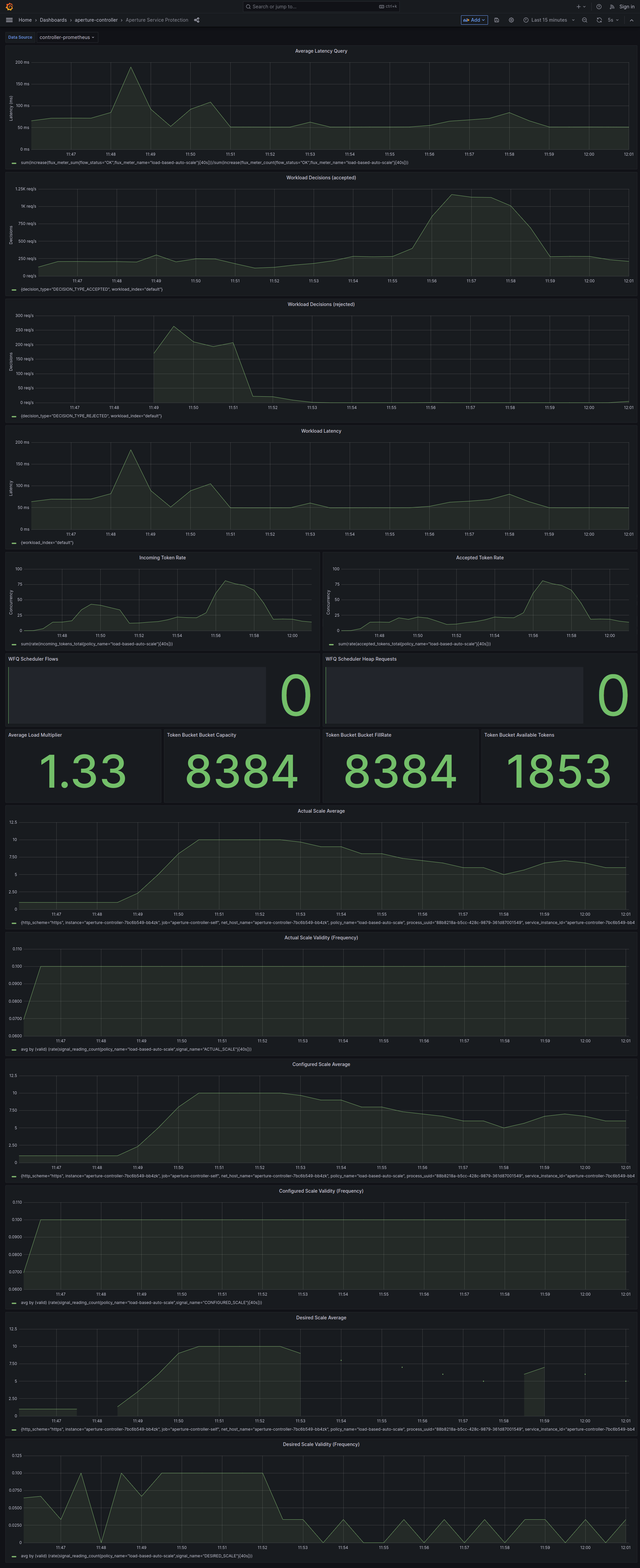
Policy in Action
During transient load spikes, the response latency on the service increases. The
service protection policy queues a proportion of the incoming requests. The
Auto Scaler makes a scale-out decision as the OBSERVED_LOAD_MULTIPLIER falls
below 1. This triggers the auto-scale policy, which scales up the deployment.
With the additional replicas in the deployment, the service is now better
equipped to handle the increased load. The OBSERVED_LOAD_MULTIPLIER rises
above 1, enabling the service to meet the heightened demand. As a result, the
response latency returns to a normal range, and the Load Scheduler ceases
throttling.
After the scale-out cooldown period, the periodic scale-in function is triggered, which reduces the number of replicas in response to decreased load.